

Remote sensing has become an indispensable tool for various applications, including environmental monitoring, urban planning, and disaster management, and many more. With the increasing availability of high-resolution satellite and aerial imagery, there is a pressing need for advanced image analysis techniques. Traditionally, convolutional neural networks (CNNs) have dominated the field of computer vision; however, vision transformers (ViTs) have emerged as a compelling alternative. This write-up explores the fundamentals of vision transformers and their applications in remote sensing.
What is a Transformer?
Transformers are a type of deep learning architecture introduced in the ground breaking paper “Attention is All You Need” by Vaswani et al. in 2017. Initially designed for natural language processing (NLP), transformers rely heavily on a mechanism called self-attention, which allows the model to weigh the significance of different words (or tokens) in a sentence, regardless of their distance from one another. This capability enables transformers to capture long-range dependencies effectively, making them adept at understanding complex relationships within data.
Key Components of Transformers:
- Self-Attention: This mechanism calculates attention scores for each token in relation to every other token, allowing the model to focus on relevant information while processing input sequences.
- Multi-Head Attention: By employing multiple self-attention mechanisms (or “heads”) in parallel, transformers can capture different types of relationships in the data.
- Feedforward Neural Networks: After self-attention, the output is passed through feedforward neural networks that further transform the data.
- Positional Encoding: Since transformers lack the inherent ability to recognize the order of sequences, positional encodings are added to input embeddings to maintain the positional information.
- Layer Normalization and Residual Connections: These techniques help stabilize and accelerate training, enabling deeper architectures.
Vision Transformers
A vision transformer (ViT) is an adaptation of the transformer architecture for computer vision tasks. It treats an image as a sequence of patches, similar to how a transformer treats a text sequence as a sequence of words. These patches are then flattened and projected into a common embedding space. The transformer’s attention mechanism is then applied to these embeddings to learn relationships between different parts of the image.
Key Differences from Traditional CNNs
- Input Representation: CNNs process images as a grid of pixels, focusing on local patterns through convolutional filters. In contrast, ViTs divide images into patches, enabling a global view from the outset.
- Architecture: CNNs rely on convolutional layers, pooling, and hierarchical feature extraction. ViTs utilize self-attention to capture relationships between distant patches, which allows for greater flexibility in understanding spatial dependencies.
- Parameter Efficiency: ViTs tend to require fewer parameters than large CNNs for similar performance levels, particularly in scenarios with ample data, thanks to their global context processing capabilities.
Typical Architecture of Vision Transformer:
A typical ViT architecture consists of the following components:
- Patch Embedding: The input image is divided into patches, which are then flattened and projected into a common embedding space.
- Positional Encoding: To provide the transformer with information about the spatial position of each patch, positional embeddings are added to the patch embeddings.
- Transformer Encoder: The transformer encoder consists of multiple layers, each of which contains a multi-head self-attention mechanism followed by a feed-forward neural network.
- Classification Head: The final layer of the transformer is a classification head, which is used to predict the class of the input image.
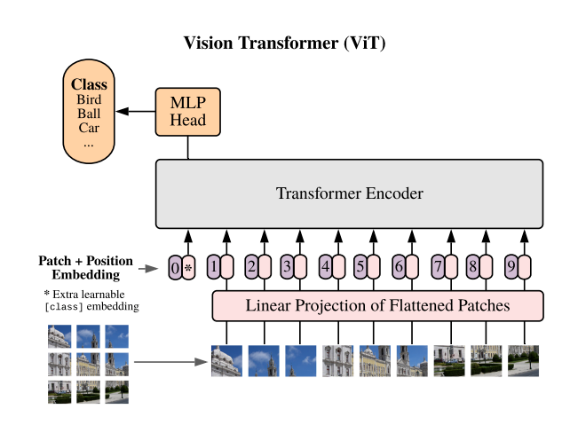
Figure 1. Vision transformer architecture for image recognition (source: Dosovitskiy et al. 2017)
Applications in Remote Sensing Imagery
Vision transformers have been applied in several remote sensing tasks, leveraging their strengths in handling high-dimensional and complex data. Here are some key applications:
- Land Cover Classification: ViTs excel in distinguishing between different land cover types, such as urban, agricultural, and forested areas, by effectively capturing global patterns.
- Object Detection: Detecting features like vehicles, buildings, and natural elements in satellite imagery can be enhanced using ViT-based frameworks, improving accuracy by leveraging the relationships between detected objects.
- Semantic Segmentation: In tasks where each pixel is classified into categories, ViTs can provide accurate segmentation maps by understanding the spatial relationships among pixels.
- Change Detection: Monitoring environmental changes over time (e.g., deforestation or urban growth) is vital for various applications. ViTs can analyze multi-temporal images to identify significant changes efficiently.
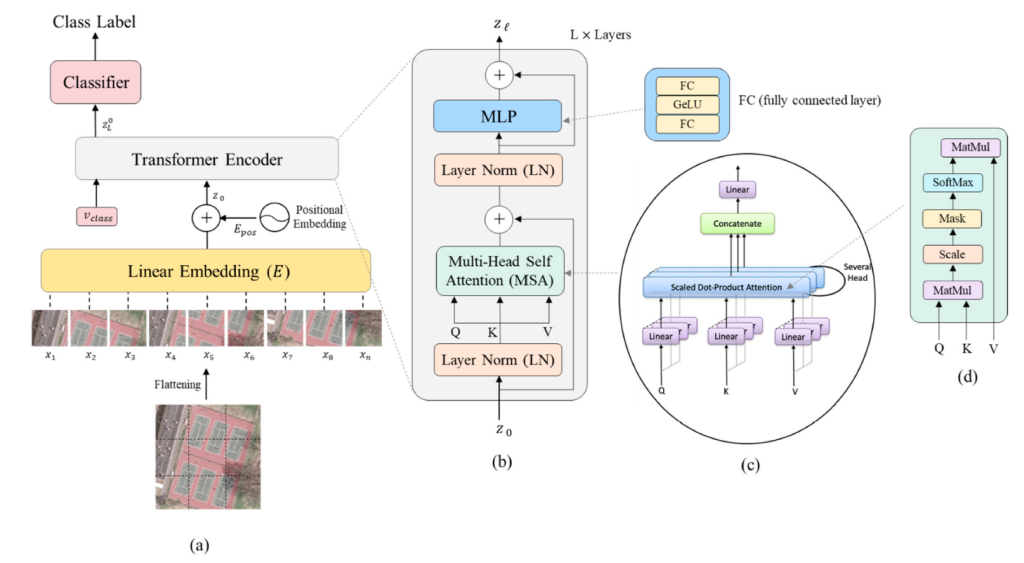
Figure 2. The Vision Transformer architecture for remote sensing image classification (source: Bazi et al., 2021)
Conclusion
Vision transformers are transforming the landscape of remote sensing imagery processing. By leveraging their ability to capture global context and learn complex spatial relationships, ViTs offer significant advantages over traditional convolutional neural networks. While challenges remain, including computational demands and data limitations, the future of vision transformers in remote sensing looks promising. As research advances and more efficient architectures are developed, ViTs could play a pivotal role in enhancing our ability to monitor and analyze the Earth’s changing landscapes, leading to better decision-making in various fields such as environmental science, urban planning, and disaster response.
References
- Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16×16 words: Transformers for image recognition at scale,” in ICLR, 2021.
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.-S.; Khan, F.S. Transformers in Remote Sensing: A Survey. Remote Sens. 2023, 15, 1860. https://doi.org/10.3390/rs15071860
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. https://doi.org/10.3390/rs13030516